OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments. Paper:
Computer Use Agents
Xiong expands upon the benchmarks, notably
WebArena, which has environments that are limited to specific apps or domains.
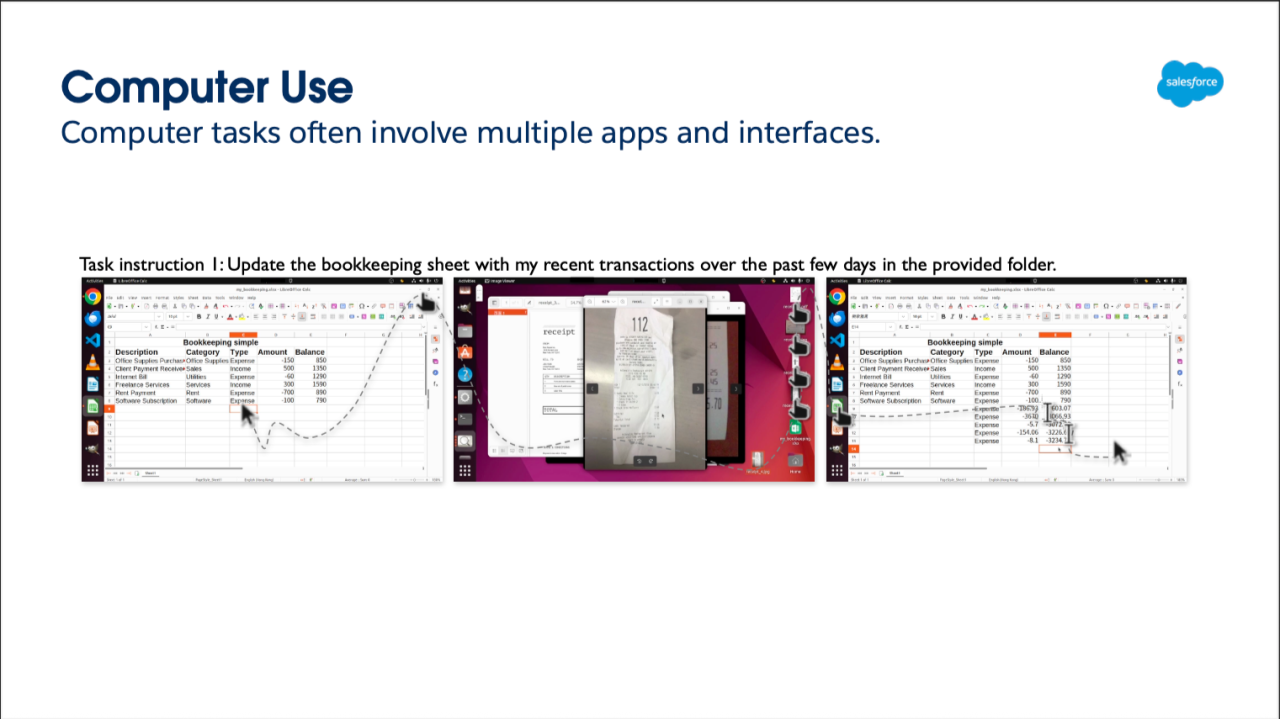
OSWorld is an attempt to tackle agent exploration with real-world scenarios navigating between multiple applications and interfaces.
OSWorld Overview Environment Infrastructure. Page 3
When I first read the OSWorld,
AGUVIS Unified Pure Vision Agents For Autonomous GUI Interaction, and
TACO: Learning Multi-modal Action Models with Synthetic Chains-of-Thought-and-Action (which talks about explicit reasoning and an inner monologue of a model) and watched Xong's lecture, I immediately thought of my conversations with some members of the Intuit AI team (A2D). I thought it would be a cool concept for Intuit to utilize AI to scan old bank statements (say they weren’t synced with Quicken or TurboTax) and would be able to input this data, transform it into CSVs, JSON, and then be able to have parseable data for TurboTax (a problem I had when I lost access to a bank account). They told this was something that they were indeed working on, which I found encouraging.
Real-World Use Case: Intelligent Commerce
AI technology has inevitably proliferated and is now being used by credit card and other tech companies (like
Visa and
Mastercard,
PayPal, and
Amazon) who are all vying for users to engage with "Intelligent Commerce," where AI agents are able to make purchases for users (some having private credit card information already pre-filled, and others manually entered.
Karan Chhina and
Cristian Douce of
auth0 gave a workshop today on how to leverage its technology to be able to make these kind of integrations seamless (not restricted to financial transactions use).
auth0 also referenced its use of Fine Grained Authorization (FGA) from Okta which was inspired by
OpenFGA (that was inspired by
Google Zanzibar) for permissioning and privacy protections in its
blog here. And Professor Dawn Song answered my question during
her last lecture on "Towards building safe and secure agentic AI" about what guardrails could exist for crypto/blockchain/web3 applications, she responded that she would hope that app developers and users protected themselves from an AI agent from gaining access to their private keys.
Cross-Platform Capabilities
See from Xiong's lecture on March 17, 2025
Xiong talks about how AI sees the data as an image shape (Web HTML DOM Tree, OS - Accessibility Tree, Mobile XML). Given this, "the action space is different, you cannot leverage different training together, not good for scalability." (See 1:12 on
YouTube).
TACO: Learning Multi-modal Action Models with Synthetic Chains-of-Thought-and-Action <-emphasis and Action
Xiong goes on to talk more in detail about creating large-scale datasets with AgentTrek (overview of how an AI agent learns by tutorials) below and incorporating synthetic chain-of-thought-and-action (TACO).
The graphic above shows common failures/inaccuracies of an LLM and how the output would be different using TACO.
Computer Use Benchmarks and Evaluations
What's great about OSWorld is that it goes beyond analyzing tasks across a single environment and extends across multiple apps. (Page 8).
And with this, we can expect to have "Agent performance has much higher variance than human across different types of computer." (Page 11).
TACO: Learning Multi-modal Action Models with Synthetic Chains-of-Thought-and-Action Paper
I am still actively working on iterating on an AI productivity app (built for iOS and Apple Vision Pro), a physical and digital productivity planner (more than a overhyped to-do list task manager) -- hopefully I'll have a version out in time for the AgentX hackathon deadline, to finally submit something substantial (lots of things to do).
Given this work, I have been researching more and more on evaluations and benchmarks. I wasn't sure if anyone would have a more robust dataset with speech-to-text (voice) that would generate a UI or have tasks similar to that of computer use--and I mean data that is inputted via a spatial computing/AR VR MR XR device. I think about this given anticipation for AR's next evolution with AI. Meta AR Glasses (Ray Bans) are all the rage. There are also anticipated releases in the next 2-3 years from Google/Samsung/QualComm's partnership for AI glasses as well as Apple (Apple Vision Pro's likely 3rd evolution after a more bulky headset, to have lightweight glasses).
I figure I might be a little ahead of the curve here, but given that iOS and even Vision Pro and Apple Watch from the Apple ecosystem are tightly intertwined, I would think that these datasets internally at Apple may be closed. Since fewer headsets have sold and with likely still, a smaller number of researchers with those from AI/ML researcher/engineer backgrounds that have the time/energy/bandwidth/resources (cost) to generate more public/open source datasets for computer use, there would be some sort of gap down the line in the future. Also note that after asking every foundation/frontier model, it's also important to distinguish between different types of data (computer use currently has been trained on web and mobile UI - flat interface data, which is distinct from the type of 3D spatial data which is different across spatial computing/AR VR MR XR devices with their respective UIs - Apple tends to be heavily scrutinized with more flat UI (which is comparable to being a complete replicates of entire mobile iOS and native MacOS applications, which is actually closer to computer use), though it also has 3D spatial data features that are comparable to experiences and applications viewed in AR VR MR XR as seen on Meta Quest and other Head Mounted Displays (HMDs).
No datasets for this exist yet as far as I have seen, though TACO has scratched the surface of spatial reasoning with regard to 3D data measuring the distance of objects as you can see in the table above, and Fei-Fei Li's World Labs focus on developing a model that achieves spatial intelligence is also exciting and promising). TACO graphic is above that shows 3D spatial reasoning results.
Speaking of which, I was thinking about the different platforms that an AI agent is currently on and views. Xiong mentioned how different it is for an agent to view data across different platforms (web, OS, mobile).
The graphic from the AGUVIS: Unified Pure Vision Agents for Autonomous GUI Interaction paper shows the differences visually an AI agent would see the shape of code per type of platform targeted (web, mobile).
Math Benchmarks, AI for Mathematics, and Conclusion
Having a computer/AI agent learn the complexity what you're doing without error (over the course of integrating multiple applications - and even cross-platform) has yet to be done (but will likely continue as open source continues to grow
I want to acknowledge that AI is by no means 100% perfect without error, as both CUA and the ability of AI to solve complex math problems still remains some of the last bits of the field of reasoning, we have yet to fully achieve on our way towards "AGI" - Artificial General Intelligence.
As Josh Tobin said in the TWIML and AI podcasts, paraphrasing that agentic AI "demos that are easy to create and looks great, but you start to (do more), ...you run into edge cases, fail modes, getting things to work reliably is really hard..,the root cause is that historically LLM are not typically trained to do agentic work. ... but as you run a process that requires many steps, the small errors at one step compound as you take multiple steps. So even if you're 90% accurate on one step, if you have to take 10 steps, then your accuracy will fall off."
The results we are getting are leaps and bounds from where we were 10 years ago, but there is a still high variance as Xiong mentioned earlier given analysis of different datasets, environments, and across different platforms.
Though throughout a good chunk of this course there was a heavy focus on code generation and AI for mathematics.
These are complex problems that will still need to continually be worked on to ensure accuracy and verifiability in its correctness of responses (especially when it comes to doing complex mathematical problems).
All of these topics in the field of reasoning ranging from: computer use, AI for mathematics, code generation, program verification are all exciting research and engineering challenges in developing the next generation of AI agents.